
O que é Apache Kafka?
Apache Kafka é uma plataforma de código aberto para streaming distribuída de eventos, que proporciona um alto desempenho para análise, integração/transformação de dados em tempo real ou quase real, e é usada por muitas empresas em todo o mundo.
Funciona através de um método de publicação-assinatura que armazena, processa (se necessário) e entrega dados a subscritores ou consumidores. O Kafka é extremamente rápido e pode lidar com centenas de megabytes por segundo, com centenas de milhares de mensagens por segundo, e com uma latência tão baixa quanto 2 milissegundos (ms).
O que é streaming de eventos?
O streaming de eventos é a capacidade de capturar informação de uma ou mais fontes – como sensores de Internet of Things (IoT), bases de dados ou aplicações –, retê-los por um certo período de tempo para posterior recuperação, e processar, manipular ou encaminhar dados para destinos diferentes, conforme necessário. Isso pode acontecer em tempo real, utilizando diferentes tecnologias.
Quem utiliza Kafka?
Bancos, bolsas de valores, fábricas, indústria do retalho, aplicações móveis, entre outros. Uma coisa a ter em mente é que o Apache Kafka não é para todos!
Existem diferentes implementações (mais pequenas, maiores), mas o facto de ser em tempo real é dispendioso. Para casos em que são gerados, processados e consumidos milhares de eventos por segundo, o Apache Kafka é uma boa opção, já que a sua arquitetura é robusta e confiável, mas pode não ser barato hospedar um cluster Kafka por conta própria, ou pagar por uma solução de serviço de Apache Kafka hospedado na cloud.
Por que é importante conhecer o Kafka?
Nem todos têm a oportunidade de trabalhar diretamente com o Apache Kafka, mas muitas soluções utilizam esta plataforma nos bastidores, pelo que é bom ter uma ideia de como funciona.
Na verdade, o Apache Kafka é utilizado por mais de 80% das Fortune 100 Best Companies to Work For. Alguns desses gigantes, conforme listados pelo Kafka aqui, incluem The New York Times, Pinterest, Adidas, Airbnb, Coursera, Cisco, La Redoute, LinkedIn, Netflix, Oracle, PayPal, Spotify, Tumblr, Yahoo, entre muitas outras.
Como funciona o Kafka?
Imagina um evento. Pode ser qualquer coisa: uma notificação, uma medição de temperatura, coordenadas GPS, etc. Os eventos são produzidos por alguém ou por uma aplicação – por exemplo, um tweet da aplicação X (anteriormente conhecida como Twitter). Esses eventos podem ser lidos, utilizados ou consumidos por alguém ou por uma aplicação. No exemplo da aplicação X, podemos publicar (produzir) tweets e também seguir alguém para ler (consumir) seus tweets (eventos).
No mundo do Kafka, os eventos são gerados ou publicados pelos produtores e consumidos ou subscritos pelos consumidores. Os eventos são gerados e podem ser consumidos a qualquer momento, precisando de ser armazenados em algum lugar. No Kafka, temos tópicos, que são responsáveis por armazenar eventos, e podemos ter diversos tipos de eventos armazenados em tópicos diferentes.
Considerando o método de publicação/subscrição, podemos ter aplicações como o YouTube ou X com milhares de canais, contas que funcionam como tópicos, criadores de conteúdo a publicar vídeos como produtores, mensagens que funcionam como eventos, e pessoas a assistir ou a ler conteúdo como consumidores. Para lidar com uma produção massiva de eventos, precisamos de uma boa arquitetura, redundância de dados e distribuição da carga de trabalho.
Para alcançar isso, o Kafka possui uma arquitetura bem definida que divide os tópicos em diferentes partições. Tópicos e partições podem ser distribuídos por vários brokers (servidores Kafka).
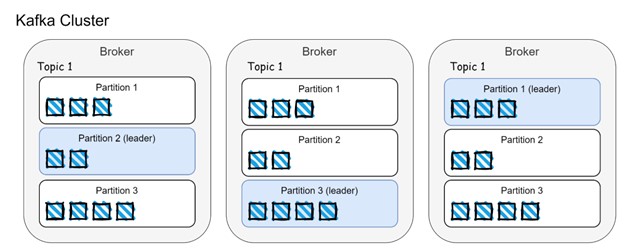
Na imagem acima, podemos ver a distribuição de dados entre brokers e partições. Os eventos são distribuídos entre as partições e replicados entre os brokers. O líder da partição é responsável por lidar com os eventos recebidos dos produtores e com os pedidos dos consumidores. Os seguidores das partições restantes (de outros brokers) replicam os dados das partições líderes e garantem que as réplicas (brokers) estão sincronizadas, também conhecidas como ISR (in-sync-replica).
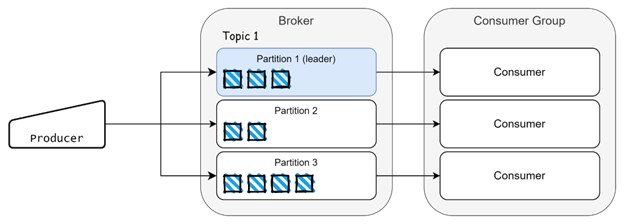
Os eventos são consumidos pelos consumidores e também podemos ter grupos de consumidores que distribuem a carga de trabalho quando é gerada uma grande quantidade de dados. Cada evento armazenado numa partição possui uma posição conhecida como offset, semelhante a uma posição numa matriz.
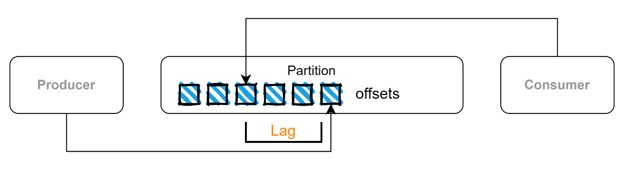
Existe um cenário em que nem todos os dados produzidos são consumidos pelos consumidores e isso pode acontecer por diferentes motivos. Voltando ao exemplo da aplicação X, podemos não conseguir ver todos os tweets publicados na plataforma, o que resulta em tweets não lidos. O mesmo pode acontecer com o Kafka e isso é conhecido como consumer lag. Os eventos são armazenados em partições numa sequência e cada evento possui um offset (uma posição dentro de uma partição). Essas informações são armazenadas em tópicos internos que contêm metadados. Portanto, o Apache Kafka “sabe” quais os eventos que foram consumidos ou não, e esse atraso pode ser um indicativo de problemas de desempenho.
Para orquestrar tudo isso, o Apache Kafka tem uma dependência central chamada Zookeeper, que mantém o controlo dos dados do cluster e coordena brokers, grupos de consumidores e eleições. É um pré-requisito para alguns tipos de implementação do cluster Kafka e deve existir antes da instalação dos brokers do Kafka. Podemos ter várias réplicas do Zookeeper no nosso cluster Kafka para garantir alta disponibilidade, conforme explicado mais detalhadamente aqui.
Integração com outros sistemas
O Kafka pode transmitir dados para outros sistemas através do Kafka Connect. É um conjunto de ferramentas de integração com plugins que podem ser utilizados com conectores e permitem a conversão/transformação de dados.
A arquitetura do Kafka Connect contém conectores para criar tarefas - as tarefas são usadas para mover dados, os trabalhadores para executar tarefas, os transformadores e conversores para transformar e manipular dados, respetivamente.
Existem dois tipos de conectores:
-
Conectores de origem, que puxam dados de outras fontes, manipulam/transformam e armazenam-nos em tópicos do Kafka (por exemplo, dados de uma tabela de banco de dados relacional podem ser extraídos, transformados no formato JSON e armazenados num tópico);
-
Conectores de destino, que puxam dados dos tópicos do Kafka, manipulam/transformam e enviam-nos para outras fontes de dados. Existem vários plugins disponíveis para gerir a integração de dados com diferentes tecnologias, como Redis, MongoDB, SAP, Snowflake, Splunk, etc.
Como utilizar o Kafka?
Existem diferentes abordagens para implementações do Kafka:
-
Instalação manual
Podemos instalar a plataforma manualmente, utilizando os binários do Kafka para desenvolvimento e testes nos nossos computadores, ou nos contentores/servidores para uso em produção. Para uma implementação mínima, necessitamos de uma instância do Zookeeper (se não estivermos a usar KRaft), pelo menos uma instância de broker e podemos utilizar scripts individuais disponíveis nos binários do Kafka para criar tópicos, iniciar produtores e consumidores para gerar e consumir dados. É possível começar facilmente com este tutorial de iniciação rápida do Apache.
-
Recurso a operadores
É possível utilizar operadores para implementar automaticamente clusters Kafka e também as suas funcionalidades (Kafka Connect, Kafka Bridge, Mirror Maker) em Kubernetes/Openshift. As opções mais populares são Strimzi e Confluent Operator. Os operadores cuidam de várias tarefas manuais durante a instalação do cluster e também facilitam o uso e a manutenção do mesmo ao lidar com a gestão de utilizadores, tópicos, alterações de configuração, etc.
-
Na Cloud
É ainda possível utilizar soluções SaaS alojadas na cloud como Confluent Cloud, Amazon MSK, entre outras.
Referências
- Apache Kafka Org: https://kafka.apache.org/
- Strimzi: https://strimzi.io/
- Confluent: https://www.confluent.io/
